Observability at scale
Grafana, Loki, Thanos, Vector, Alloy. Stack audits, migrations, query performance work, SLO dashboards, and platform hygiene.
I help engineering teams debug faster, reduce operational noise, and harden the platforms behind critical services.
Available for freelance missions - Paris area / remoteGrounded SRE in real production operations. Focused operator for teams that need automated reliability, not tickets.
Grafana, Loki, Thanos, Vector, Alloy. Stack audits, migrations, query performance work, SLO dashboards, and platform hygiene.
Kubernetes operations, Helm, Argo CD, CI/CD (Jenkins, GitLab), Terraform and Ansible automation for safer, repeatable delivery.
Virtualization and distributed storage on bare metal. Multi-datacenter clusters, migrations from legacy virtualization, HA and network design.
For teams that need AI capabilities without sending data to third-party clouds: local LLM serving, private RAG pipelines, and AI-assisted diagnosis running entirely on your Proxmox/Kubernetes infrastructure. GDPR-compliant by design, full control over models and data.
A few receipts from 10 years operating infrastructure that can't quietly fail.
Operated multi-cluster observability at multi-TB/day ingestion across logs, metrics, and traces, with Kafka pipelines feeding SIEM, logging, EDR, APM, and uptime monitoring.
Integrated a highly available automized Proxmox cluster with Ceph storage, PXE automation, and 200 Gb networking per host.
Led automated VM and application delivery across 10 datacenters and 4 providers (OpenStack, Proxmox, vSphere, K8S) from shared Terraform templates.
Tools I build around real operational pain points, kept practical, open, and useful beyond my own environment.
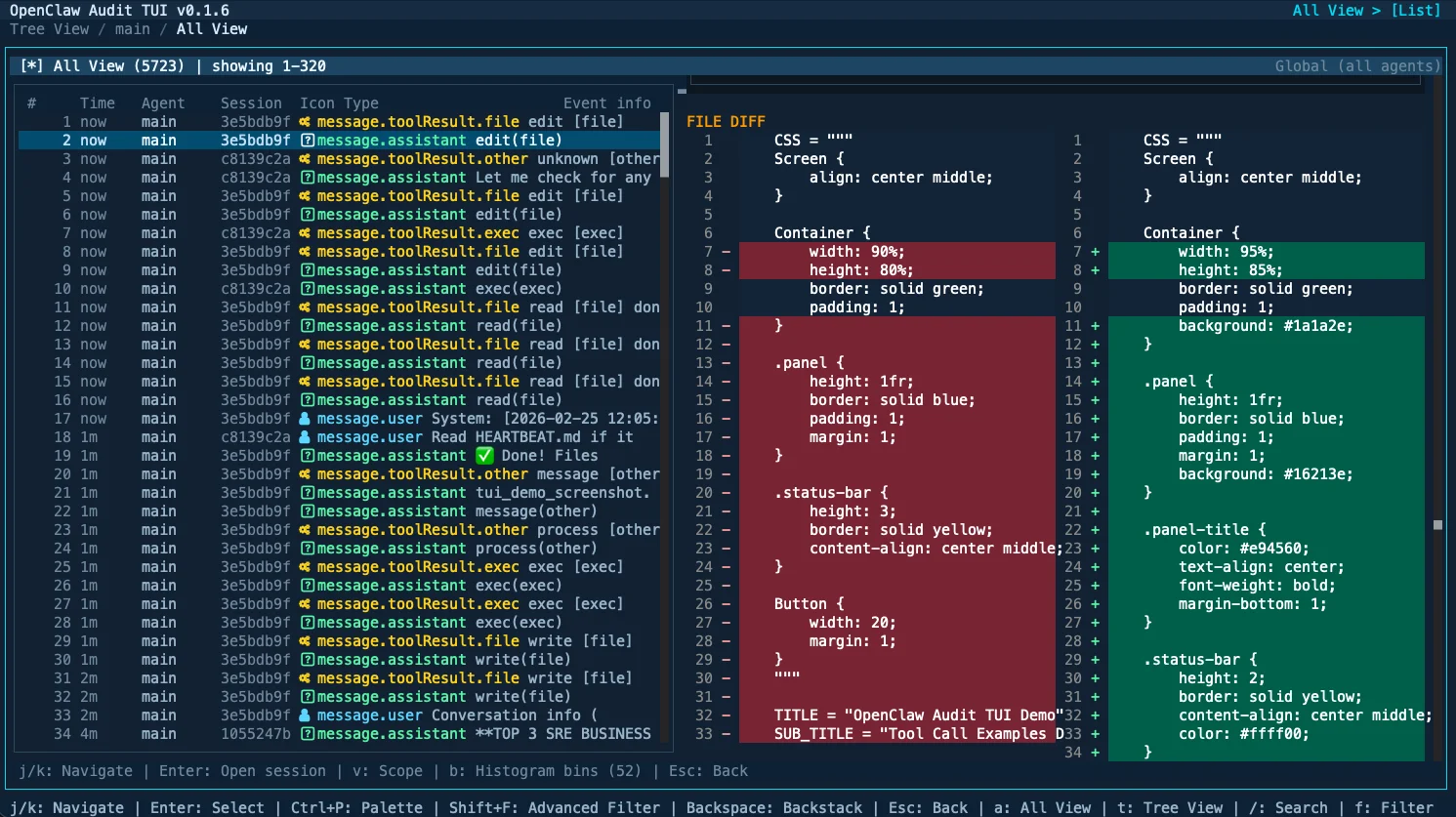
Terminal audit UI for OpenClaw sessions with live events and real-time streaming.

Terraform provider for Centreon API V2, monitoring configuration managed as infrastructure as code.
If your team runs critical infrastructure and needs SRE work that doesn't add theatre, get in touch.
Email me